
Today, Arm is unveiling its updated Neoverse roadmap. For those who have missed the branding campaign, the Arm Neoverse brand is for Infrastructure Servers to Edge. Effectively, Arm has branded its core IP that chip designers can use. The current generations of Arm server chips are based on the Neoverse N1 and E1 platforms. This can include chips such as the Ampere Altra and AWS Graviton2. As part of its disclosure today, Arm is discussing the Arm Neoverse V1 and Neoverse N2 cores which will be the foundation of future infrastructure chips.
The Quick Recap of Where We Are
Arm’s current roadmap progress shows that the company promised a 30% annual performance uplift, but achieved a 60% performance uplift with N1.
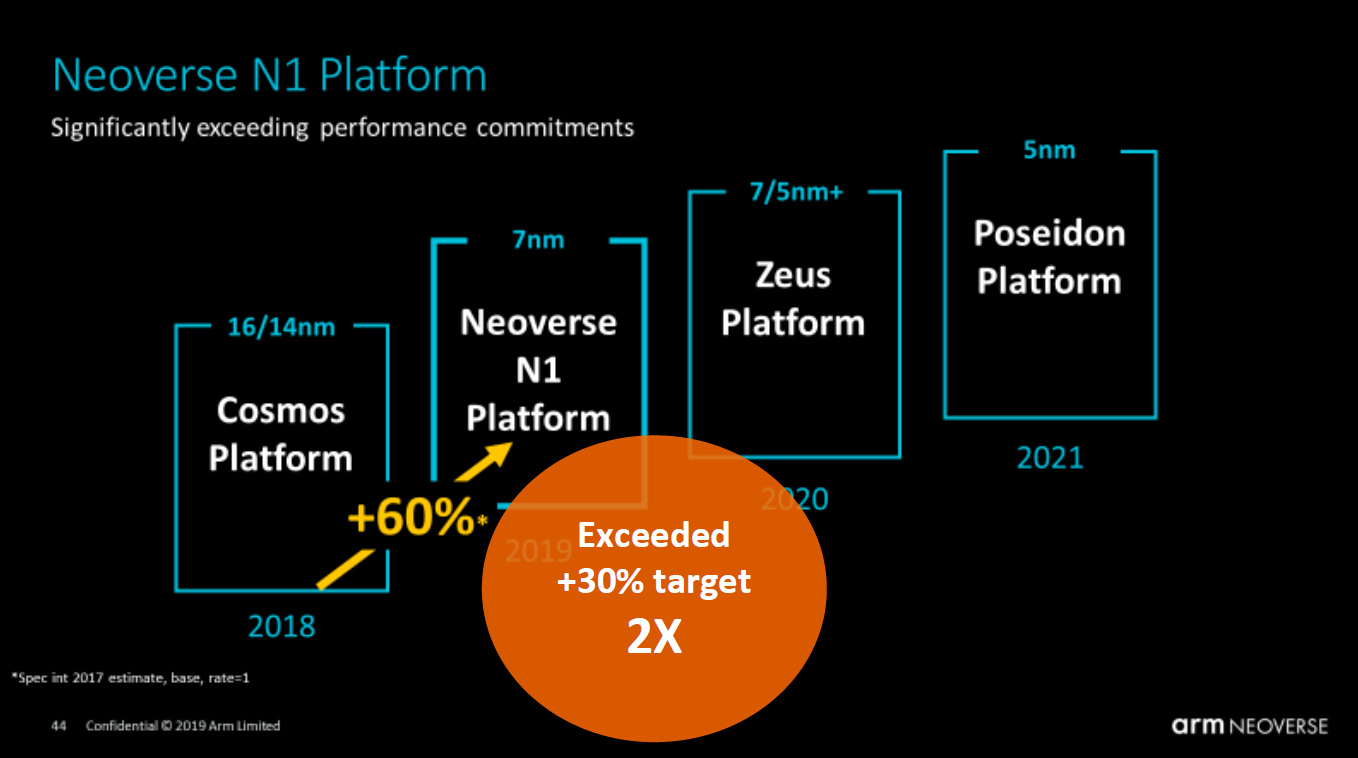
Arm is focusing on how it enables hyper-scalers to build their own chips, bypassing 3rd parties. A great example of this is how all of the performance numbers are being quoted using a Graviton 2 processor, instead of something like the Ampere Altra. We will quickly note here that one has to remember these cloud provider benchmarks are relevant within the AWS ecosystem, but not necessarily outside of it. Amazon AWS controls the hardware and pricing of its Arm and x86 architectures. That may seem like a nuance, but it is also an important distinction. The more that AWS can push workload to its processors, versus ones it purchases from others, the better off AWS is and it controls instance sizing and hardware to help make that happen.
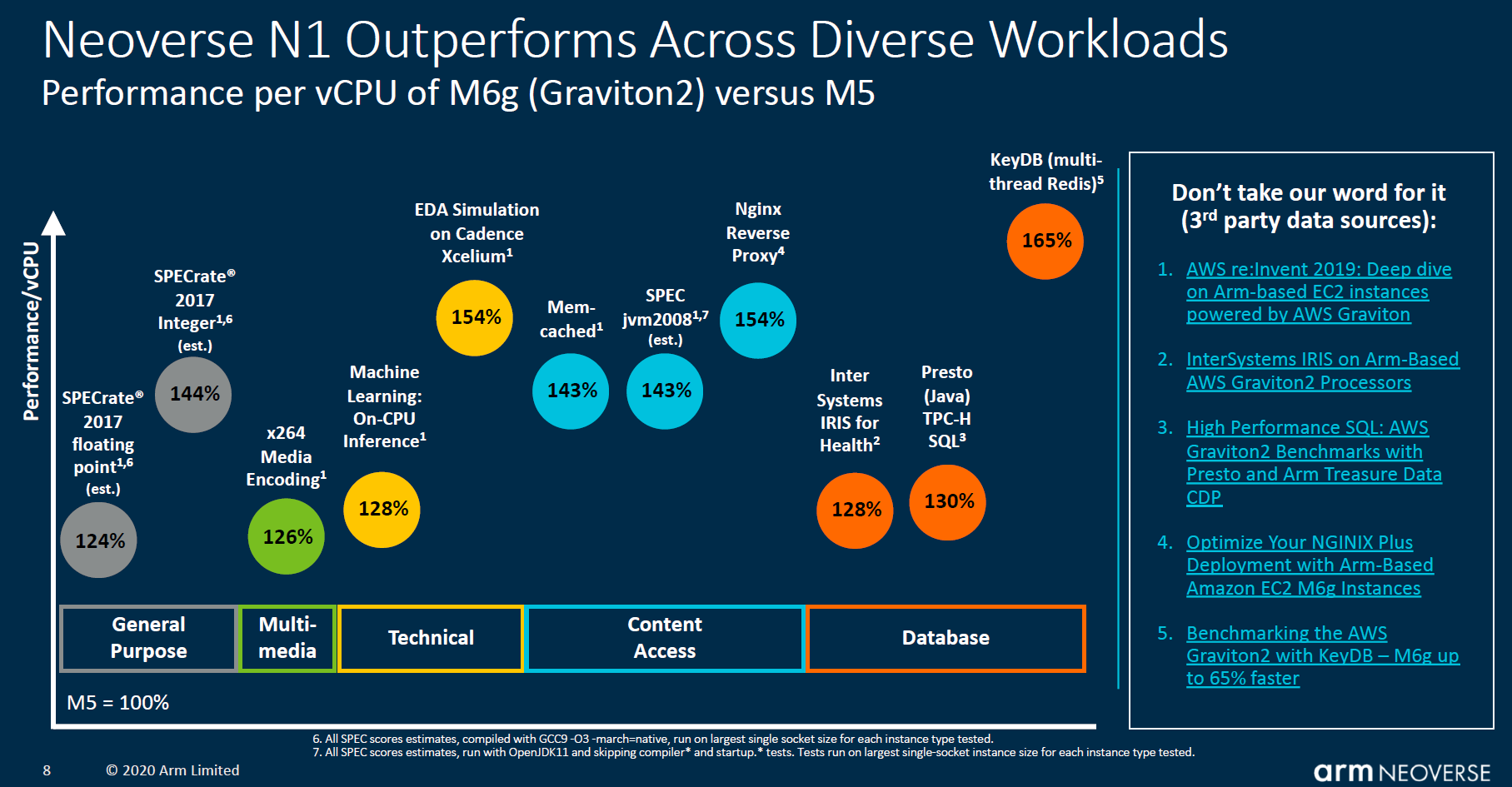
Arm also is focusing Neoverse N1 on integer math and is using an Intel Xeon Platinum 8268 for this comparison showing rack density using estimates. Effectively it is saying 40x dual Xeon Platinum 8268 systems fit in the same power consumption envelope as 4x dual 80 core processors. As a result of having more cores, it says it achieves more aggregate performance. For a cloud provider, this means more performance per rack and more saleable instance volume if a cloud instance is tied to a measure of performance.
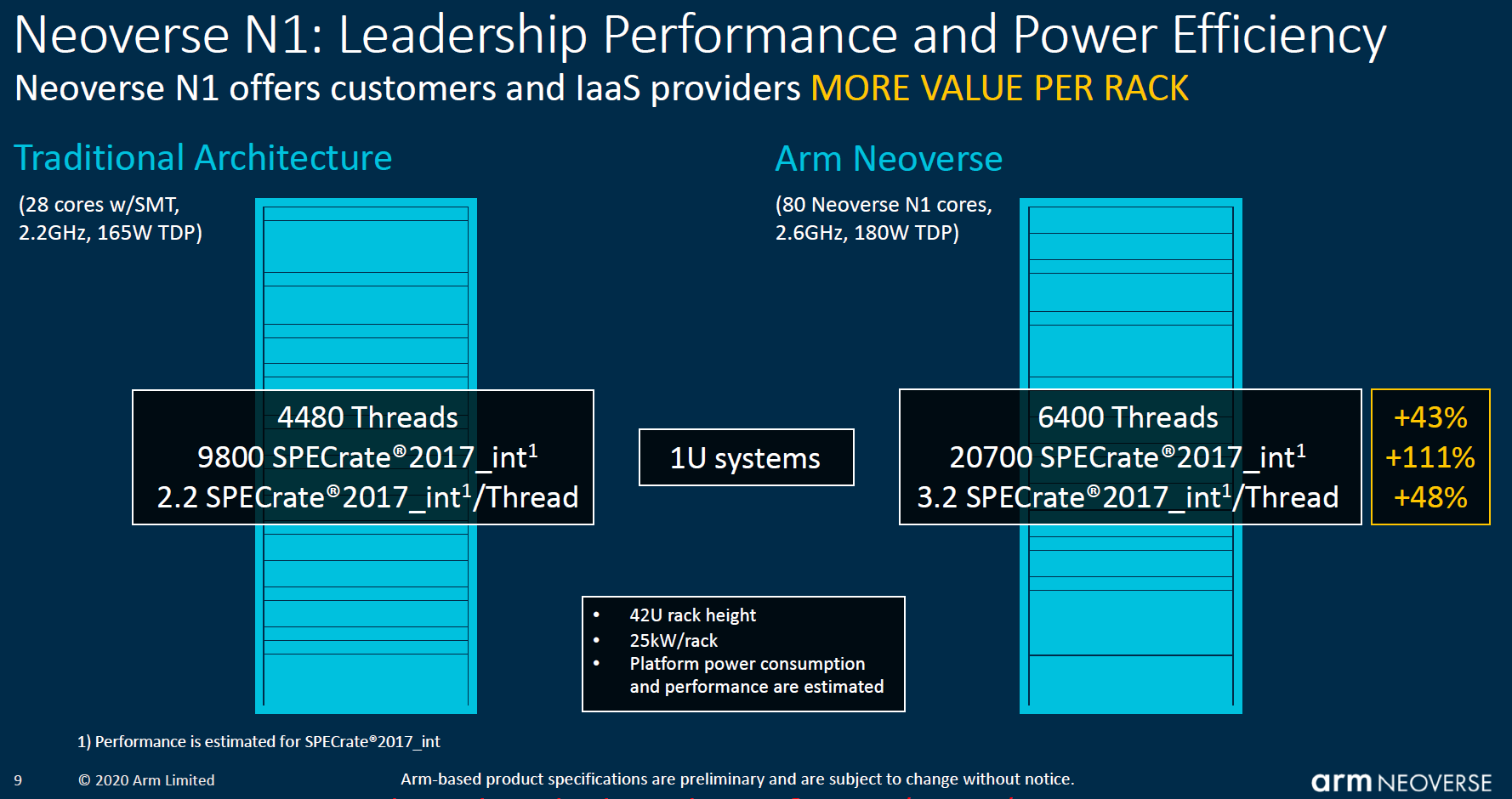
Arm is effectively comparing something like an Ampere Altra 80 core CPU here to an Intel Xeon Gold 6238R. Arm is de-rating the Intel solution from published SPEC numbers by 24% by taking the ICC numbers and using a 0.76 ratio to convert to GCC 8.2. Alternatviely, one can use a ~12900 for the aggregate SPECrate2017_int estimated performance x86 line and 2.9 for the per thread performance. GCC is a valid metric to use, but we wanted our readers to also to see the delta on a compiler optimized basis.
It is little secret that Intel’s performance has not been incrementing at a great rate here, but we should remember that we are effectively talking about a lower volume Arm product that has a handful of platforms just hitting commercial availability and the tail end of Intel’s 2019 (or as we covered in The 2021 Intel Ice Pickle How 2021 Will be Crunch Time really a 2017) architecture. In that time, AMD EPYC has been advancing at a significantly faster rate and now is pushing 64 cores/ 128 threads per socket and we have seen instances of better per-thread performance such as with the AMD EPYC 7F52.

We are not saying these are bad comparisons, just when Arm makes announcements on cores, it is important to remember the context is different than when Intel or AMD are releasing products. In other words, you can go get the x86 side shipped to your door from a number of vendors, in a number of form factors tomorrow, but that is not currently possible with Neoverse N1. Arm N1 may be ~10% ahead of Intel here, but that is not necessarily a great look in the competitive context of AMD EPYC 7002 “Rome” which was released over a year ago and is set for a refresh in the next quarter or two.
With that background that we are just hitting Neoverse N1 availability, Arm is announcing its next-gen IP details.
Arm Neoverse 2020 Roadmap
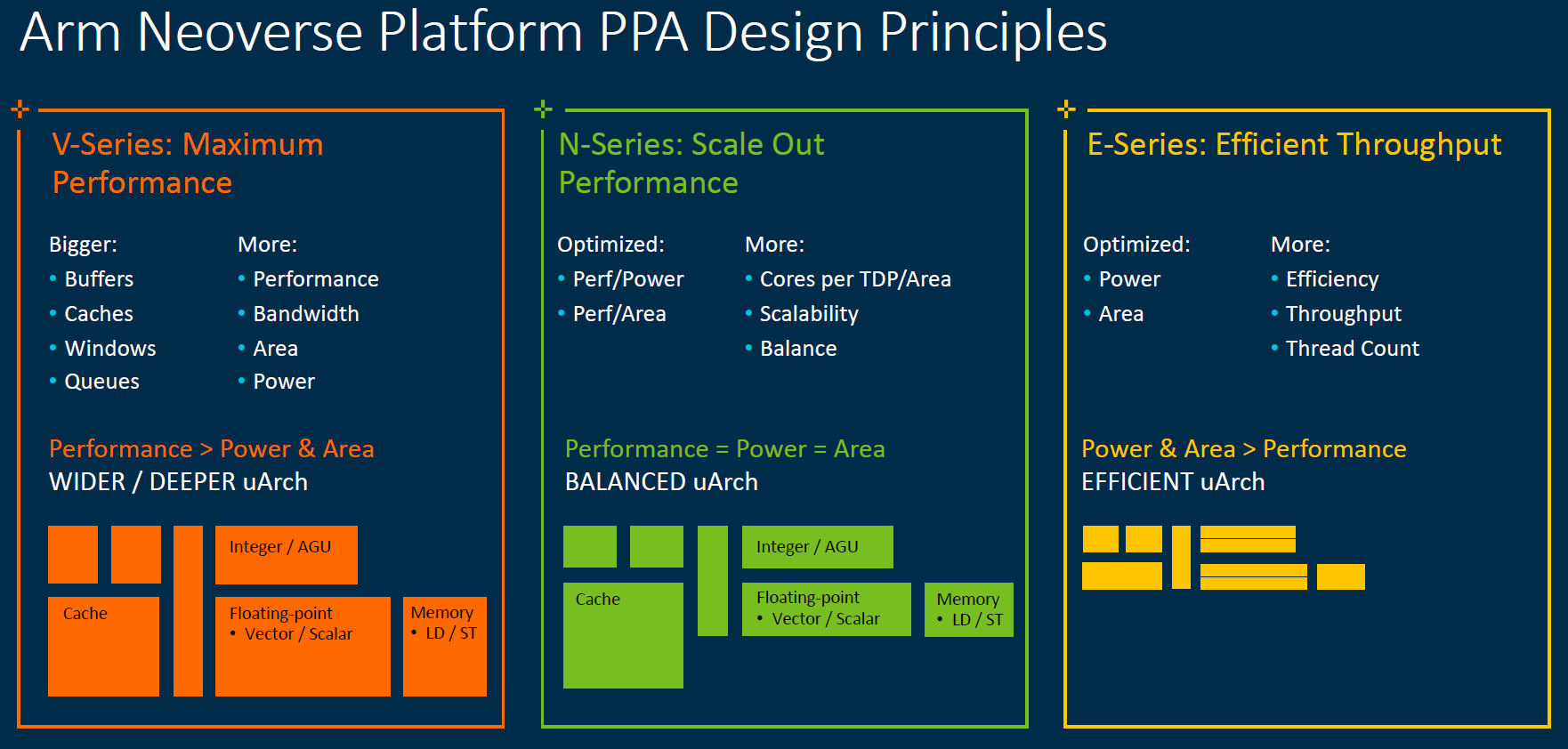
New for this announcement are disclosures around the Neoverse V1 and Neoverse N2 platforms. Formerly, these were Zeus and Perseus on the roadmap. The Arm Neoverse V1 platform is designed for large single threaded performance gains in the near-term. On the longer-term, the Arm Neoverse N2 cores will provide almost equivalent single threaded performance uplift, but with less floating point perormance.
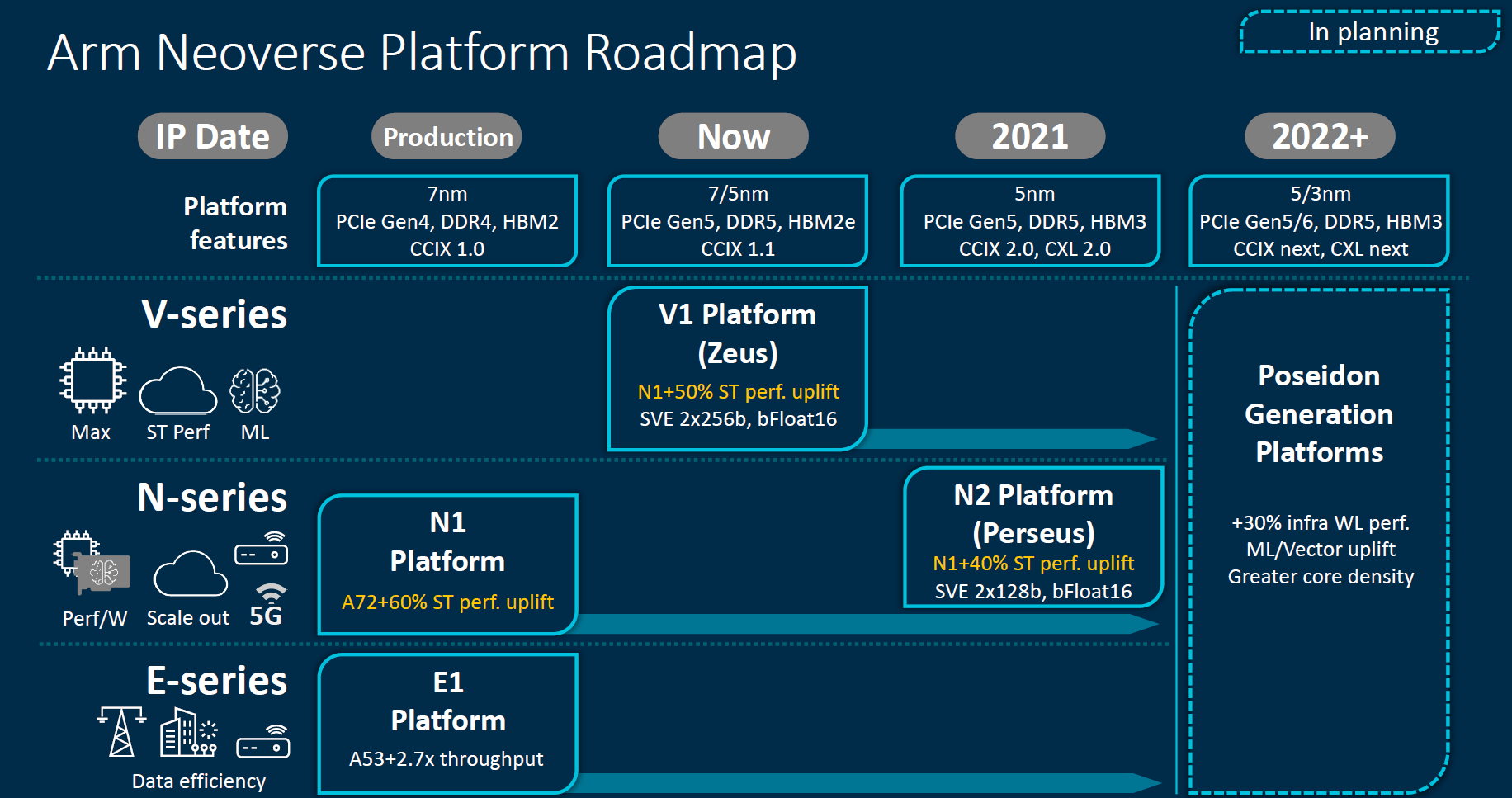
Since this V1 and N1/N2 split is new, Arm gave some sense of how it is segmenting the lines. Effectively, the V-series is design to trade efficiency on the power and area axis for more performance. The N-series will be focused on hyper-scale cloud instances. The E-series will be focused more on maintaining small physical and power footprints.
Another point Arm showcased was how it is thinking about next-gen packaging and intra/inter-chip communication. Today, CCIX is used by Arm chips like the Ampere Altra, and companies like Xilinx were big proponents of the technology. We know that in the future, CXL is the way forward starting with the PCIe Gen5 generation for in-system communication. Likely we will have Gen-Z make an appearance outside of the system unless some major integration work happens. Arm is betting on CCIX to form its chiplet communication structures.
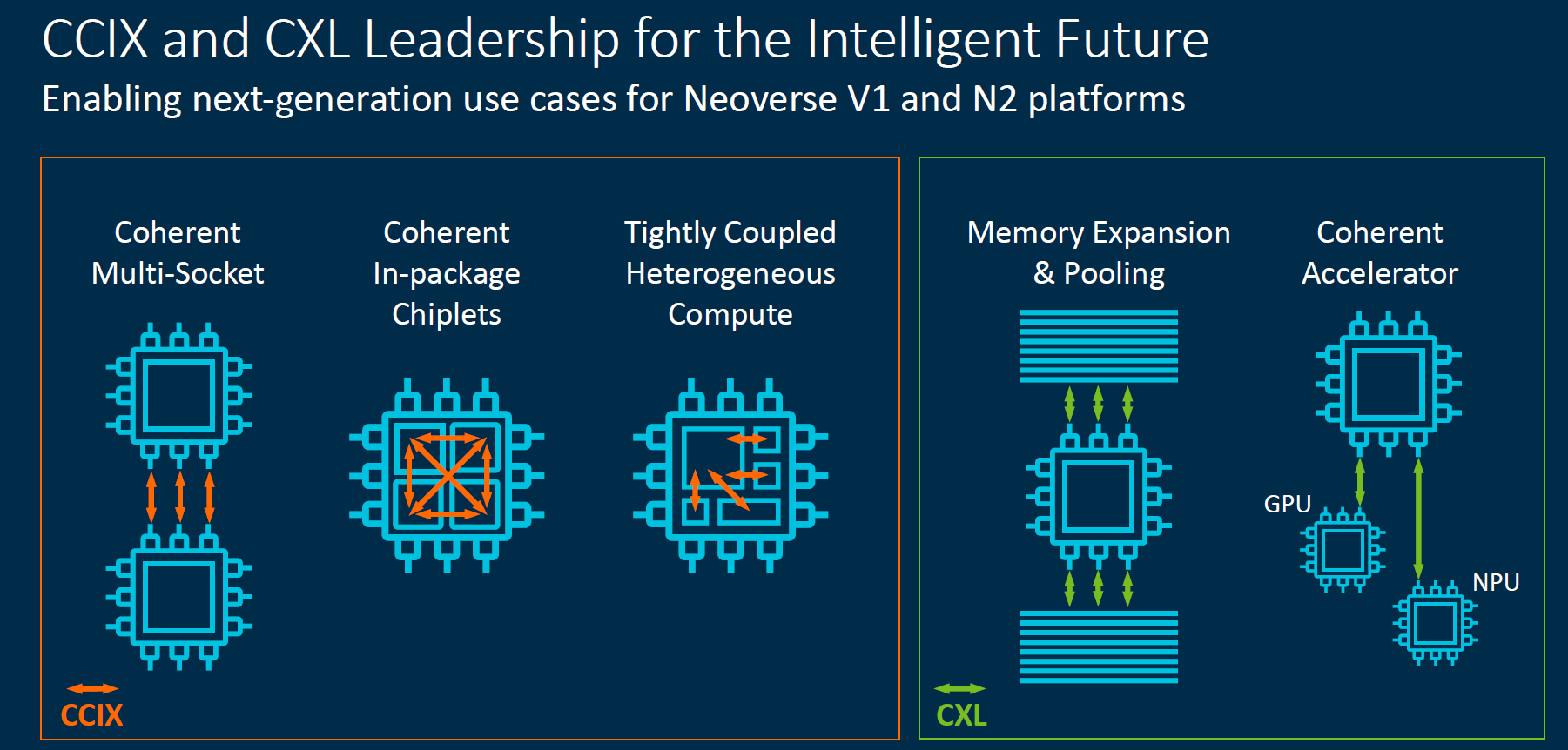
Let us take a look at what those mean for products although we were somewhat disappointed not to get an E-series update to share.
Arm Neoverse V1 Series
First, we have the performance oriented Neoverse V1 series. Despite the leadership slide offered in the announcement, this is designed to be CCIX only, not CXL enabled even as a PCIe Gen5 device. We expect Gen5 devices from most other vendors to include CXL. It is designed to be implemented in 7nm and 5nm and also to integrate HBM2e.

Bolstered by Supercomputer Fugaku by Fujitsu and RIKEN arm is capitalizing on SVE for its AVX feature alternative. The integration of HBM here is interesting for use cases like the A64fx where extreme memory bandwidth can be enough of a benefit to spin custom silicon. Beyond SVE, Arm is also planning to support bfloat16 which has become a requirement from many cloud providers.
Something that x86 architectures typically have focused on is the ability to execute anything reasonably well. If you noticed above in Arm’s benchmarks, most were focused on integer workloads which is a traditional strength of Arm architectures since one can optimize for those use cases and get better efficiency. Neoverse V1 feels like Arm’s move to get a parity of perception around Arm chips as being capable of running anything.
Arm Neoverse N2 Platform
The Arm Neoverse N2 platform has a different focus. Its goal is to be more integer performance focused and be used to scale to large numbers of cores and to smaller core counts, especially coupled with accelerators.
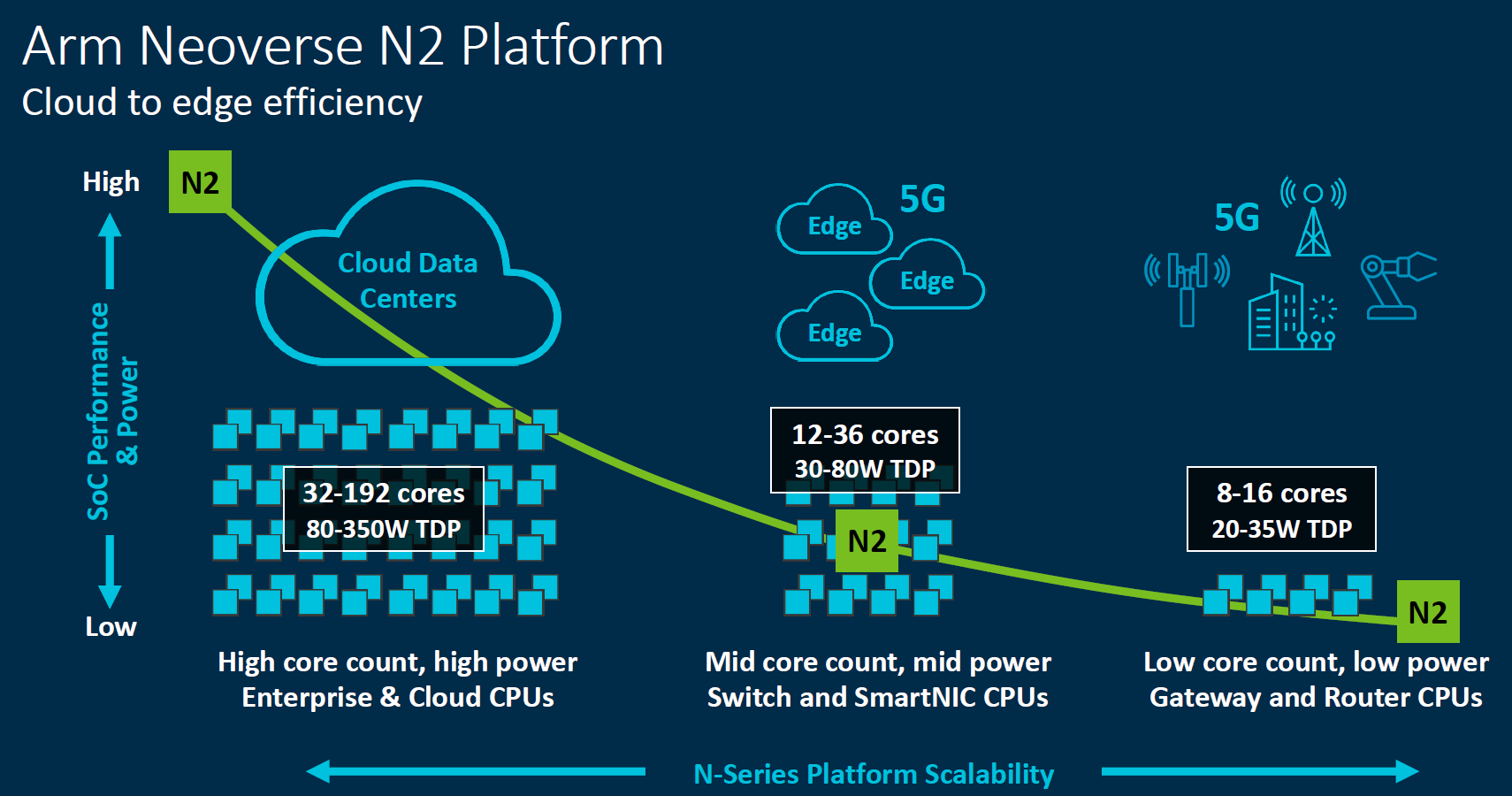
This is the true successor to the Neoverse N1. It is a 5nm focused IP with PCIe Gen5 support, CXL support, HBM3 support, along with DDR5 support. In 2021 it will be joined by not just the new “Milan” EPYC 7003 generation launching later in 2020, but by the “Genoa” EPYC 7004 generation. On the Intel side, in theory this will be contemporaneous with Sapphire Rapids Xeons but depending on timing it may also fall into competition with Ice Lake Xeons and/ or Granite Rapids generations. While features such as DDR5, PCIe Gen5, and CXL seem impressive today, that will be the industry norm when this generation arrives.
Arm Neoverse N2 and Neoverse V1 Performance Expectations
In terms of positioning, Arm expects these parts to be well ahead of x86 architectures from Intel and AMD that are shipping today, at least on the integer side. Again for context here, Arm is using the Intel Xeon 8268 and AMD EPYC 7742 here and using GCC 10 as the compiler. We are also looking at what is effectively 2017-2019 x86 architectures compared to a 2020-2021 Neoverse N1 architecture and future Neoverse V1 and N2 products. Timing is important to keep in mind when looking at existing volume production products versus new IP announcements. In some ways, this is like looking at the IBM POWER10 announcement where we will have systems available more than a year after the disclosure.
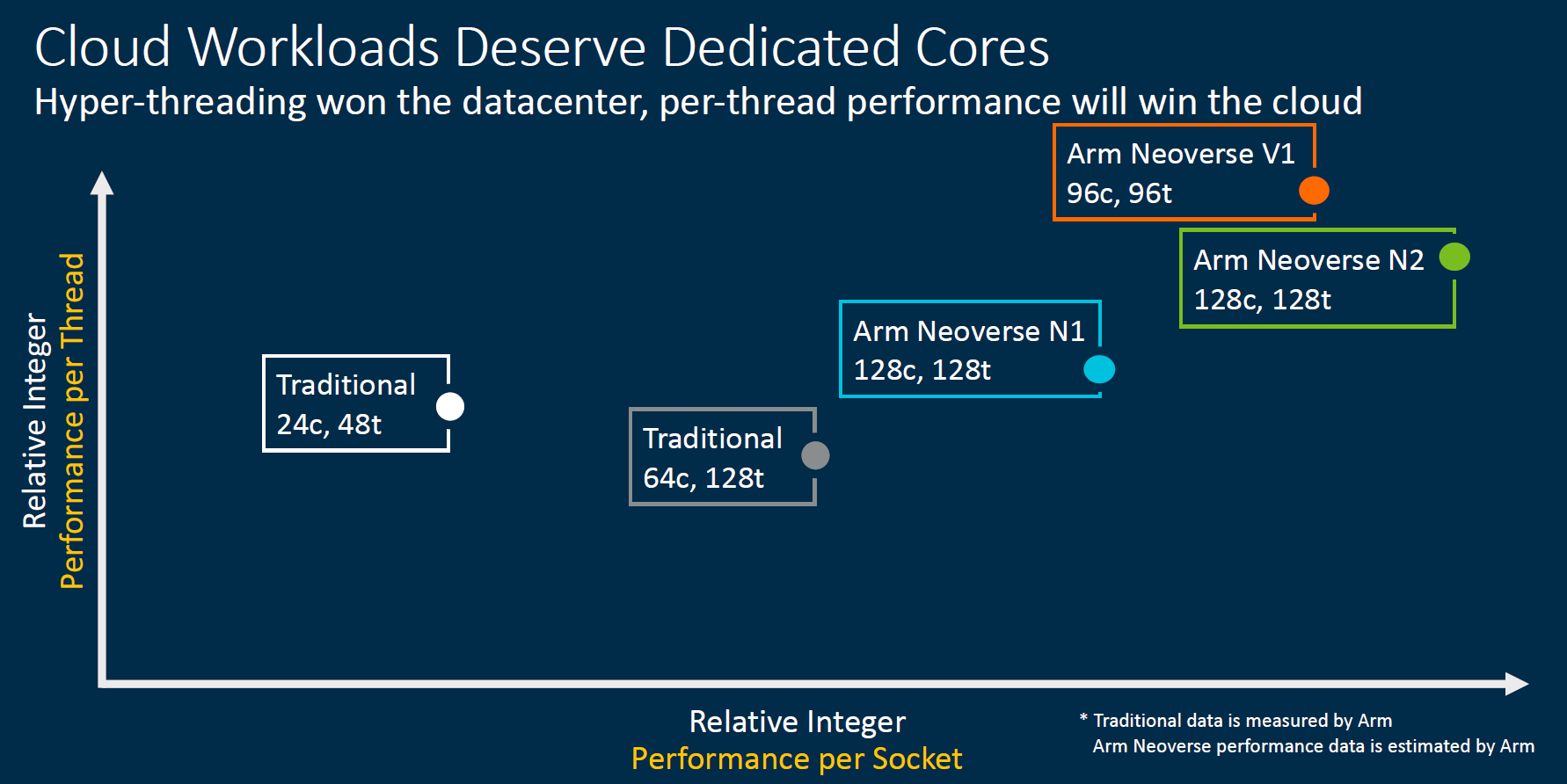
The impact of the Arm Neoverse V1 and N2 is that a cloud provider can tune performance per core/watt or for more cores in a rack.

Again, we have to see what the actual products become, but there are a lot of interesting options. Arm is looking to provide these options not just for the highest core count chips but is looking to how they can integrate with other systems for application-specific processors as well.
Final Words
Re-reading the above, it may seem we were a little picky on how Arm presented data. Since we were presenting the slides, we wanted to give the benefit of some of the end note slides that accompany them. To us, the context is important. At least Arm is making this information available which is a great effort.
For our readers, the other important context item is to remember that Arm announces cores, but that is not a product. If you call your Dell or HPE sales rep today and ask for the PowerEdge or ProLiant with a Neoverse V1, N2, or even a N1 CPU, you will likely get redirected to x86. An Arm launch is different than an Intel/ AMD launch and is perhaps more akin to the IBM POWER launches in terms of time to product.

Where Arm is focusing on is the next wave of application processors. This is where cloud providers tailor farms of cores to create specific instance flavors, as AWS showed with Gravition 2. In the next wave of compute, we have to think about which chiplets work together and how they interact. We need to think of larger coherent memory systems. We need to think about the role of processors ranging from SmartNICs to Fungible F1 DPUs/ Pensando Distributed Services Architecture devices. Arm’s strategy is to push more solutions into the market to enable architectural creativity.
As always, stay tuned to STH for more as the Arm Neoverse V1 and Neoverse N2 products go from IP blocks to physical products.



{kind=link}
Currently, only a 4 core SDP is available for ARM licensed developers: https://developer.arm.com/documentation/101489/0000/Hardware-description/N1-SoC?lang=en – a much higher core count would certainly generate a lot of interest.