
At SC19 the Top500 November 2019 edition was released. Twice per year, a new Top500.org list comes out essentially showing the best publicly discussed Linpack clusters. We take these lists and focus on a specific segment: the new systems. Something was certainly different. The number of new systems on the June 2020 Top500 list (#55) is only 58. That is a vastly lower number than the June 2019 (94) and November 2019 (102) lists. We are going to make some wild speculation as to the reason as to why that may be. We already covered perhaps the highlight of the new list with Supercomputer Fugaku by Fujitsu and RIKEN Revealed at No. 1. It is time to get to the numbers.
Top500 New System CPU Architecture Trends
In this section, we simply look at CPU architecture trends by looking at what new systems enter the Top500 and the CPUs that they use. Let us start by looking at the vendor breakdown.
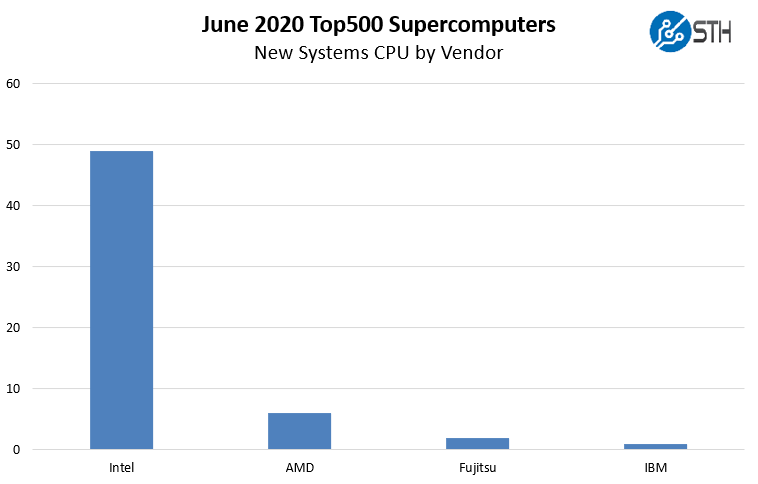
In June 2020, while Arm took the top spot, and the A64fx had another new system on the list, x86 was installed on 55 of the 58 new systems with IBM Power taking a single new system win. When we break this down by architecture:
This is extremely interesting. We have seen some of the more unique options from previous lists such as the Xeon D (Broadwell-DE) not present. Perhaps the most notable absence is the Xeon E5 generations of CPUs. In the November 2019 list, we had 18 Xeon E5 V3/V4 systems. Another interesting point here is that AMD EPYC 7001 “Naples” is not on the list from the company’s 2017 generation but the EPYC 7002 claims six spots. Intel still has 20 systems or almost 34% of the new systems on this June 2020 list using its 2017 generation Skylake architecture. When we remove those, we get a different picture:
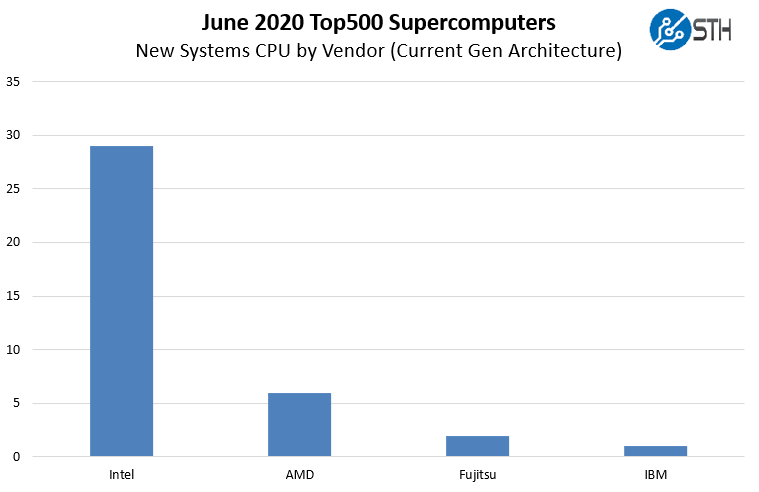
Intel still has a commanding share here, but if we look at current architectures that share is slightly more muted. Intel has around 83% of the new systems, but if we remove Skylake systems, Intel has around 76% share. We will track in the future if this delta continues to increase if customers continue to use older generations of non-Intel CPUs.
CPU Cores Per Socket
Here is an intriguing chart, looking at the new systems and the number of cores they have per socket.
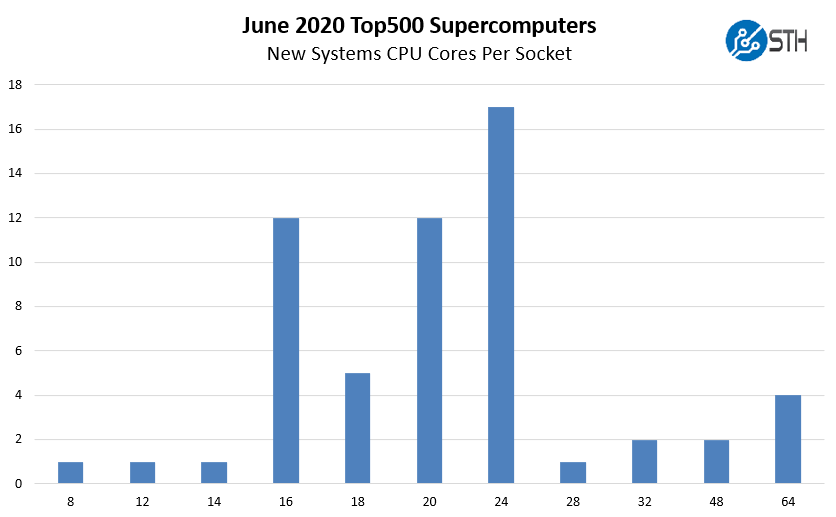
Previously 20 cores were the most popular option. Now, we see 24 cores as the sweet spot. A year ago this chart in the June 2019 list only scaled to up to 28 cores. We now have 8 systems with 32 cores and greater on the list. From 0% a year ago to almost 14% on this list. Here is a list of all the CPUs added to the list:
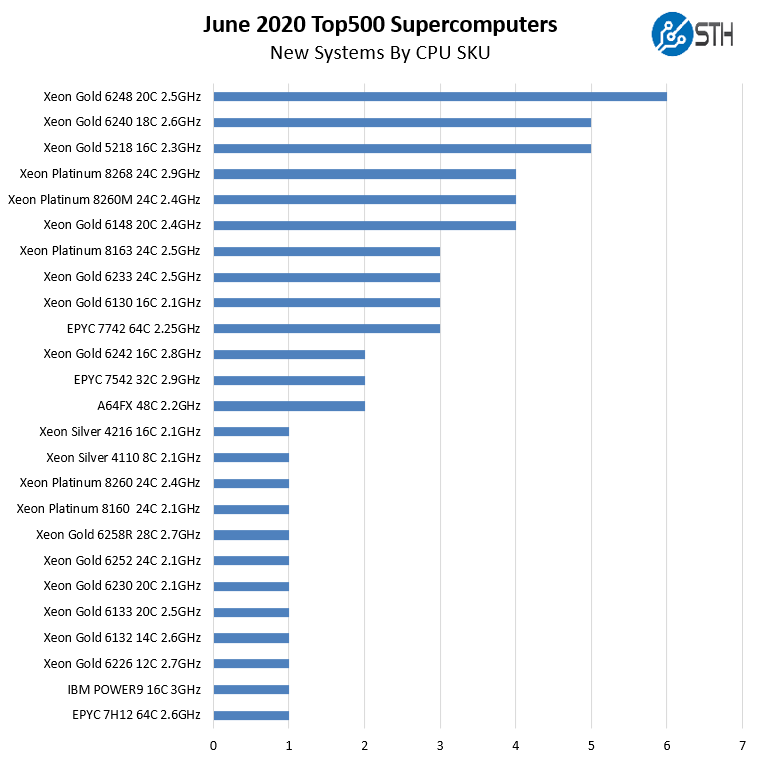
Perhaps the most interesting point here is that Intel’s highly touted Intel Xeon Platinum 9282 56-core part did not make the list while AMD’s top bin HPC SKU, the AMD EPYC 7H12 managed a single new system on the list. The Platinum 9200 series is still being positioned as the HPC CPU for scaling cores in a socket and will remain that option in Intel’s portfolio for some time. Although it was launched for HPC, it failed to add a new system to this list.
Accelerators or Just NVIDIA?
Unlike in the June 2019 list, NVIDIA is not the only accelerator vendor for the new systems. Here is a breakdown:
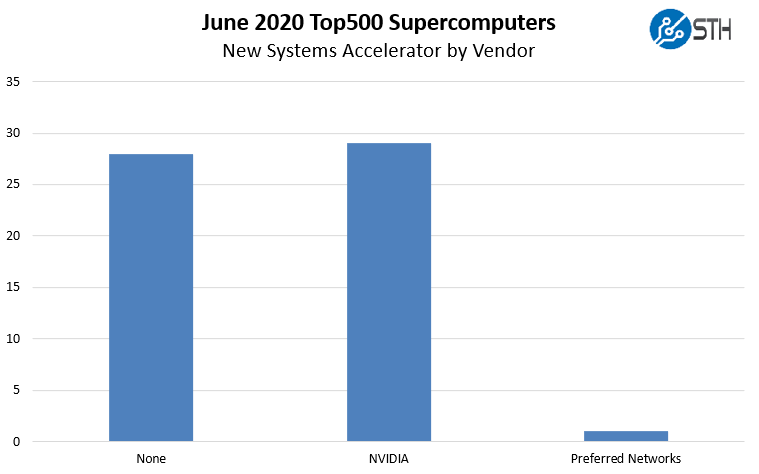
Half of the 58 new systems are using NVIDIA accelerators with 28 of the 29 accelerated systems using its GPUs. Here is a breakdown of the new accelerated systems:
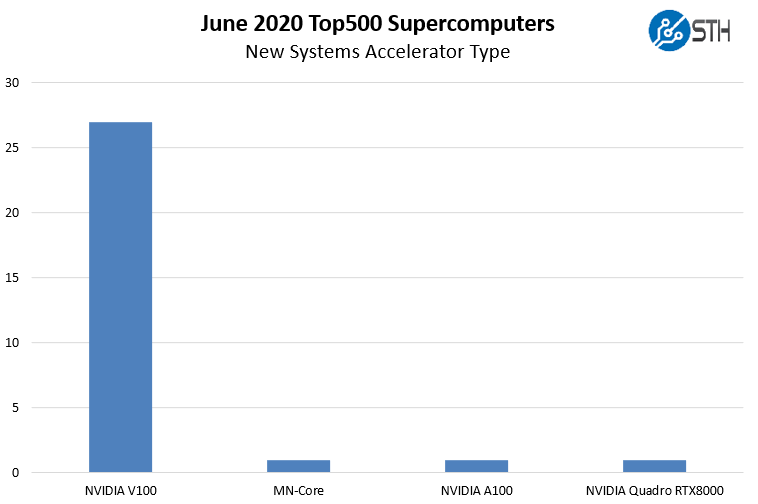
As one can see, the NVIDIA V100, no longer the “Tesla V100” is still the dominant accelerator. The lone NVIDIA A100 spot belongs to NVIDIA’s own internal system. The lone standout here is the MN-Core solution. If you are not familiar with that since it has a smaller market share, here is a presentation:
Acceleration is still a NVIDIA game, but with Exascale systems coming soon, and we know about AMD with Frontier and El Capitan 2 along with Intel Xe HPC GPUs for that era, we may see a change over the next few lists as high-end systems get more diverse with accelerators. What is a bit stunning here is that while AMD had a Vega 20 system enter the previous list, it did not see an entry here. Perhaps this is why the DoE is investing in software tooling to make AMD and Intel GPUs viable since NVIDIA effectively owns the HPC acceleration market with the caveat that CPU-only is the primary alternative.
Fabric and Networking Trends
One may think that custom interconnects, Infiniband, and Omni-path are the top choices on the Top500 list’s new systems. Instead, we see 31 of the 58 new systems or 53%, using Ethernet. This is down from around 75% in June 2019 and 59% in November 2019.
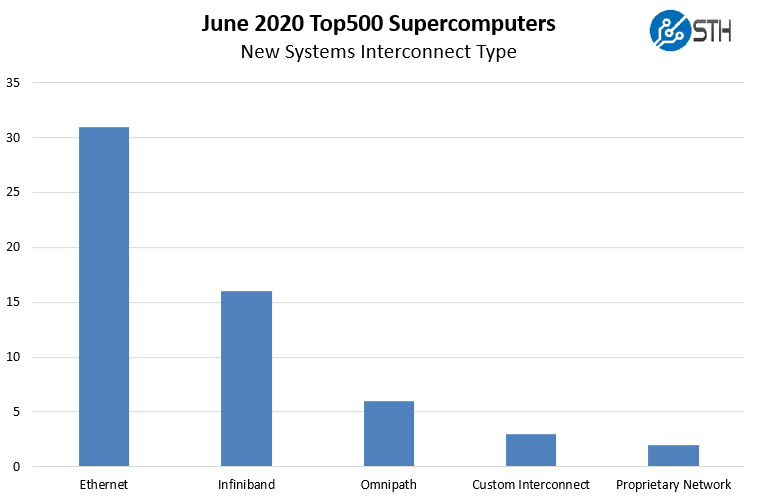
It is somewhat surprising here that OPA remains so popular. Many have known Intel’s current interconnect was being sunset since SC18, and the product line officially has no roadmap beyond 100Gbps. Still, we see around a tenth of the new systems with OPA100.
When we look at a breakdown by type and speed, here is what we get:
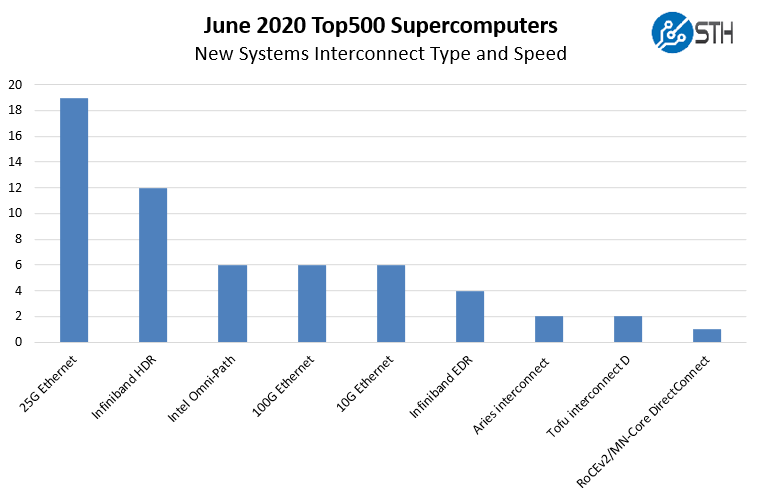
As one can see, common web-scale interconnects, namely 25GbE is extremely popular. These are lower performance and lower cost interconnects typically used by hyper-scale and similar companies in general-purpose infrastructure. Notably, 40GbE is not present in the new systems on this while it has been used on many previous Top500 entries. 10GbE has also seen a massive drop-off.
If we drill into which manufacturers are using 10GbE, 25GbE, and 100GbE to be consistent with our previous analysis, here is what we get:
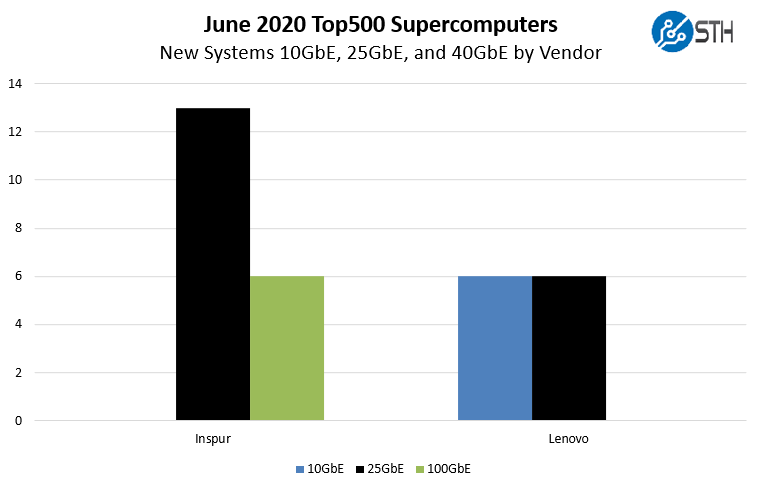
As one can see, Lenovo maintains 10GbE supremacy. Inspur has several customers using 25GbE but also 100GbE. There are quite a few GPU clusters using 100GbE because it is easier to integrate into existing IP networks.
Final Words
When we look at the vendor picture, we can get a sense of what is happening in the market:
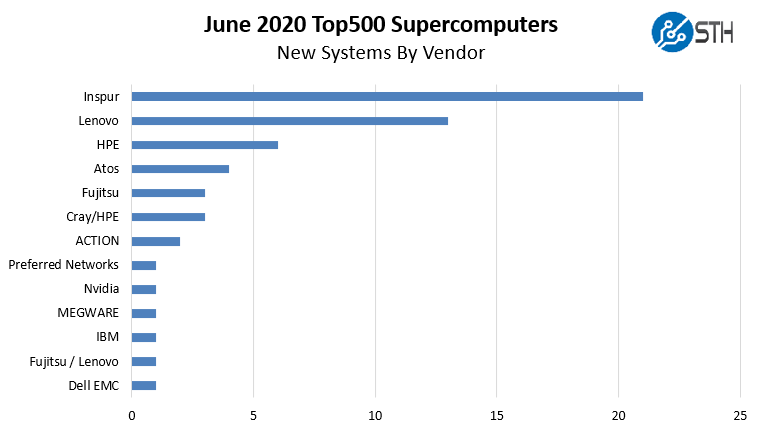
Inspur had a strong showing. One extraordinarily interesting point is that one of the most popular systems from Inspur was the Inspur Systems NF5468M5 that we reviewed. We noted our test system had been used for some time before our review. This was because the system came from a trial for a large internet company in China. It just so happens three of the new supercomputers on this list (#147, #148, and #149) are using the same configuration with the Intel Xeon Gold 6130 and the site listed is “Internet Company” for this Top500 list. There is a good chance of our review system being very similar to a node installed in those clusters.

Lenovo seems to have stopped the practice of having a large number of 10GbE systems on the list from benchmarking segments of service provider clusters. We also wanted to note that Dell EMC had a single new system which was surprising. For the top server vendor to have only one new system added to the list is borderline shocking.
The other obvious point here is that the sheer number of supercomputers added to the list is 50-60% of what is typical, despite the #1 spot shifting. Part of that is likely due to global changes that have happened this year. One is left to wonder if that is the driver, or if folks are looking to Exascale already and thus we are seeing pullback on current generation spending.



{kind=link}
I love these analysis pieces you do. They’re a great way to step back from all the announcement hype
Maybe I am missing something, but some of the numbers just don’t match up.
You start with “The number of new systems on the June 2020 Top500 list (#55) is only 58.”, however, shortly after you write “x86 was installed on 56 of the 59 new systems” so there is already a difference between either 58 or 59 new systems.
Then again the 58 in “Half of the 58 new systems are using NVIDIA accelerators” before completely switching gears to “Instead, we see 60 of the 102 new systems or 53%, using Ethernet.”, where the 60 out of 102 does not even match the graphic right below. Rather the graphic shows 31 systems using Ethernet.
So is it 58 (most likely), 59 (probably off by one) or 102 systems (???), or am I missing something here?
Thank you for the analysis Patrick!
Do you see the trend of unbenchmarked, custom-made supercomputers for the absolute cutting-edge, extremely well-funded AI outfits (and the new breed of Bioinformatics startups for that matter) accelerating?
I.e. in the spirit of the Azure system, which was custom-built for OpenAI (https://blogs.microsoft.com/ai/openai-azure-supercomputer/)
@L.P. – Top500’s linpack benchmark is just irrelevant to AI workloads – no one uses double precision in training or inference. We know Google has a fleet of 100PF class systems… at bfloat16 precision. Even the NVIDIA-based AI systems are benchmarked on fp64 CUDA cores for linpack while actually using fp16 tensor cores for real work.
The alternative benchmark is MLPerf, but by all indications it’s a huge effort to run and only the vendors are interested in it.
While number of systems is interesting, the new Japanese machine is equivalent to 227 machines from the middle of the list. Since the speed of the different machines on the list varies over more that two decimal orders of magnitude, it seems better to tabulate the different architectures based on total aggregate capacity. In particular, ARM (as well as Power) are actually looking much more successful than the current way of presenting the data suggests.