
Last week, we covered the Intel AI Summit 2019 where the company unveiled more about its AI chip portfolio. At Supercomputing 2019, Intel did a pre-briefing that did not do the keynote justice. The 7nm Intel Xe HPC GPU is absolutely something to get excited about as the company showed more details at the Intel HPC Developer Conference event across from SC19. If you missed our first piece based mostly on the pre-briefing, check it out here. Intel’s Sapphire Rapids Xeon, adoption of CXL, and particularly the oneAPI project are all important ecosystem components surrounding the GPU announcement.
Setting the Stage for the Intel Xe HPC GPU
During the keynote, Raja said that originally, the company was looking at what amounts to today’s GPU market. They realized that there was an opportunity to build a GPU less focused on graphics, and more focused on the compute and architecture necessary for exascale and high-performance computing.

Intel has the Xe LP architecture for sub 20W and potentially up to 40-50W for low power and efficient processing. Xe HP was set to go to the higher power range. Xe HPC is much more compute versus graphics optimized with higher power and voltage. Intel did not disclose exact power consumption, but we expect this will happen in the next year or two.

With that stage set, it is time to talk about the Intel Xe HPC Ponte Vecchio GPU.
Intel Xe HPC Ponte Vecchio GPU
Intel split the discussion into compute and memory. Intel is using a variable vector width and is able to handle SIMT and SIMD styles. Intel said its bit performance gains happen when both are utilized.

The actual execution units, Intel says it can scale to large numbers. We will get full specs at a later date.

Intel is following NVIDIA’s lead and is building a matrix engine into its GPUs. Intel is innovating here with INT8, bfloat16, and FP16 data types supported. Intel is introducing bfloat16 support in Cooper Lake during 2020 and in its AI chips as well. The industry has focused on the data type for AI and Intel is running with that direction.

Since we are at SC19, Intel showed its future double-precision prowess stating a 40x gain in performance.

As exciting as the compute side is, the memory clearly won the day. The Intel Xe HPC Ponte Vecchio GPU will feature CXL links for a coherent interconnect between GPUs and CPUs. This is the answer to the NVIDIA NVLink, and what will be the next generation. The compute and HBM will be connected to the XEMF which provides the memory fabric.

There is also a giant RAMBO cache. Pausing for a second, calling your cache Rambo, was insanely cool. John Rambo is Sylvester Stallone’s iconic action character and probably what went through the minds of 99% of the audience. With the big cache, Intel thinks it can mitigate performance loss from using larger matrices that you see today. With NVIDIA GPUs, one can see the impact of cache sizes on performance as problems scale. Rambo takes care of that.
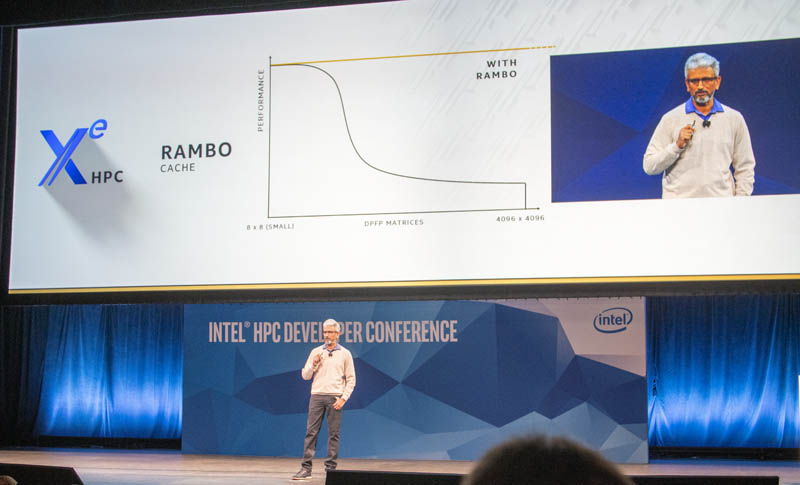
Intel is using EMIB for its HBM interconnect to the fabric. Rambo cache uses Foveros packaging.

Intel also took another jab at NVIDIA with the Reliability for Exascale section that many missed. It is offering Xeon class RAS and ECC across memory and caches. The big one here is that “in-field repair” which is a barb against NVIDIA SXM2 / SXM3. As someone who has done SXM2 installation, in How to Install NVIDIA Tesla SXM2 GPUs in DeepLearning12, they are not easy compared to the hundreds of CPU installations we do each year. This was a thinly veiled jab at NVIDIA.

Here is the Ponte Vecchio Intel Xe HPC Exascale GPU.

Final Words
Being clear, this is a great direction for Intel and 2021 will be exciting. More precisely, it may be 2022 that will be more exciting depending on when this all comes together and is sold. Still, if one looks beyond Intel’s 2020 lineup, the subsequent generation will be the game-changer. CXL will usher in a new era as server architectures change.



{kind=link}
Intel must stop talking and start delivering.