Second Generation Intel Xeon Scalable Security Hardening
The industry was hit by several side-channel speculative execution exploits starting in January 2018. Ever since Spectre/ Meltdown, more have surfaced. Some like the L1TF/ Foreshadow have been exclusive to Intel. With the new “Cascade Lake” architecture in the 2nd Gen Intel Xeon Scalable processors, many of these have hardware fixes.

Note, Variant 1 was not addressed in this generation. There are many customers who want this as soon as possible. Intel shared a bit on performance.
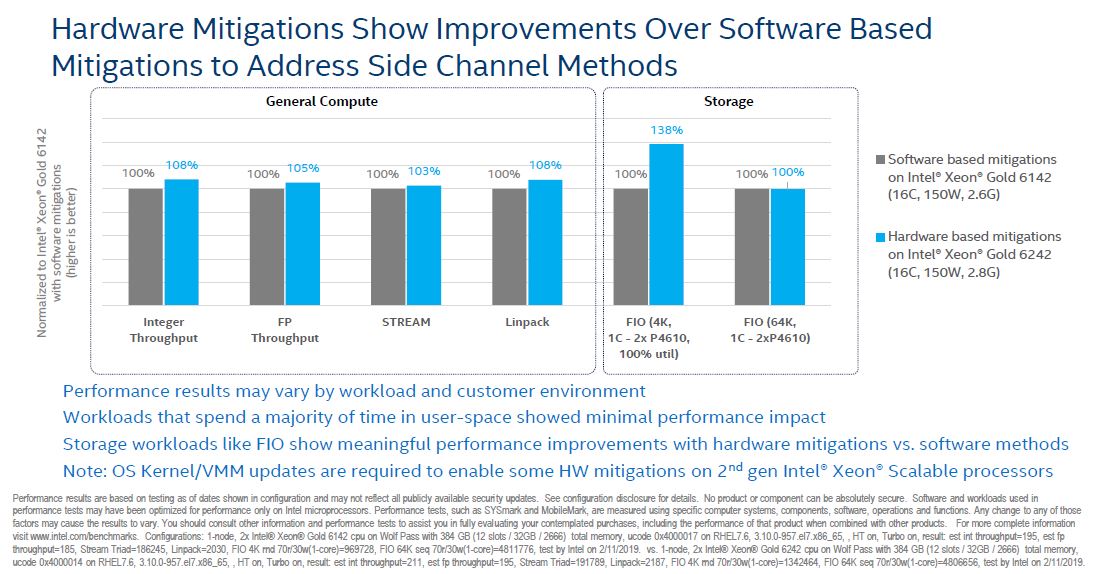
At first, one may think that this shows enormous performance gains. Note that in comparing the Intel Xeon Gold 6142 to Xeon Gold 6242 Intel benefits from a 200MHz base clock jump. That gives about a 5.5-7.7% clock speed boost alone which is what is driving most of the performance gains here save the loaded FIO test that is dramatically different.
Intel Deep Learning Boost
Do not be fooled by the name of this feature. Enabled by the new VNNI instruction, Intel is accelerating AI inferencing at the edge. Intel Deep Learning Boost or “DL Boost” for short, enables accelerated INT8 math operations.

This VNNI accelerator one can think of as an Integer counterpart to the AVX-512 floating point enhancement that Intel released with the Skylake-SP generation.
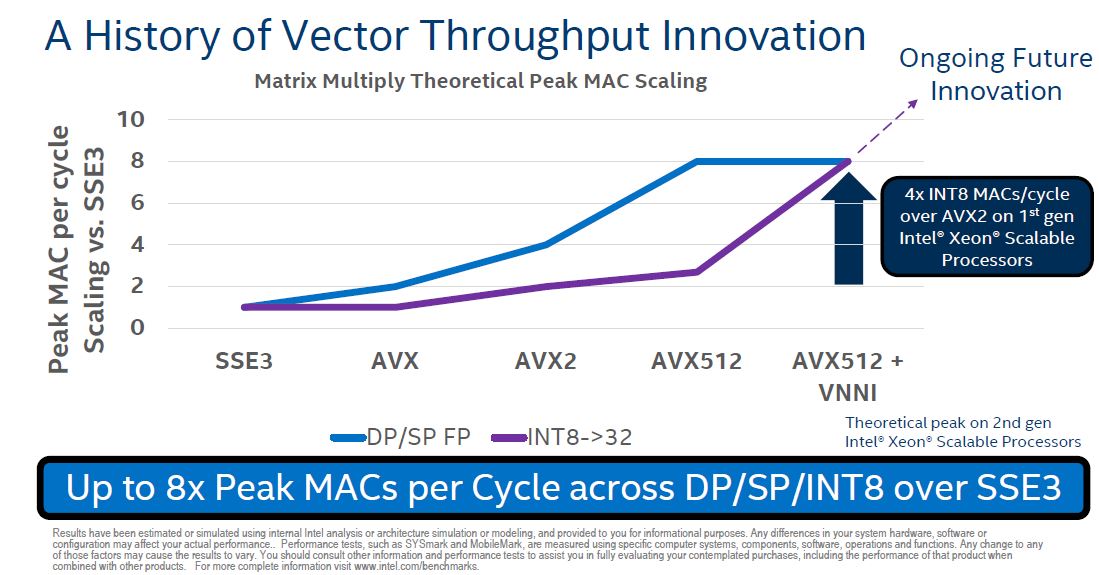
With only 256 possible options, INT8 is less computationally taxing than FP16 and utilizes less memory. As a result, Intel is able to do more with its CPUs. Losing precision is often seen as acceptible in inferencing to gain performance and lower power consumption.
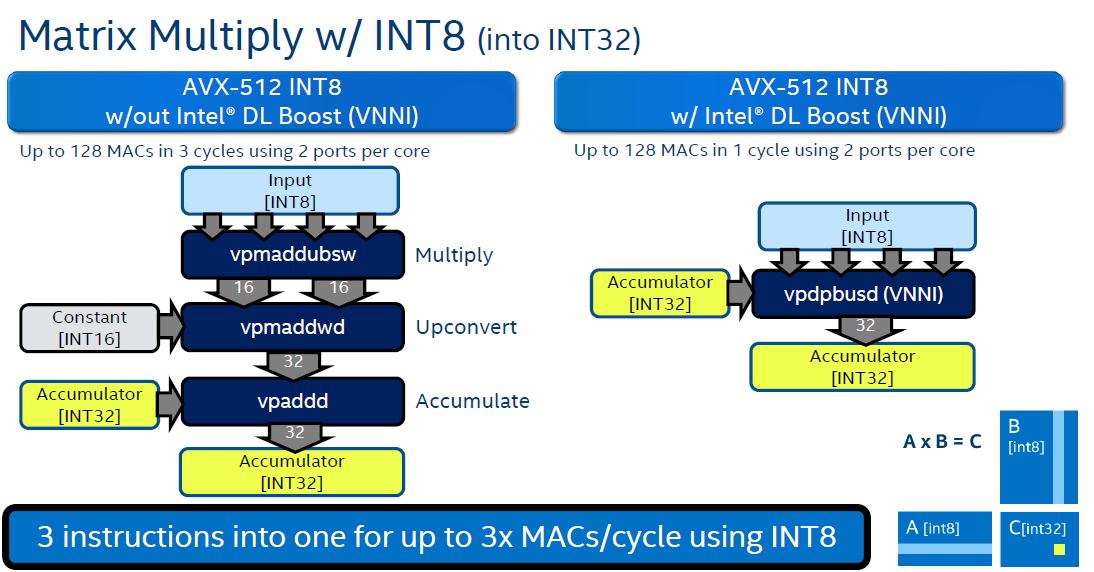
Intel’s hope is that DL Boost in this generation allows more data center, HPC, and edge inferencing without requiring customers to utilize GPUs like the NVIDIA Tesla T4. This is not a feature that will threaten the NVIDIA Tesla V100 for deep learning training. Intel has several products in the works for that.

Intel provided a few examples of INT8 versus FP32 across a number of common reference workloads to show how it impacts performance. One can see that one can do more multiply accumulates with VNNI.
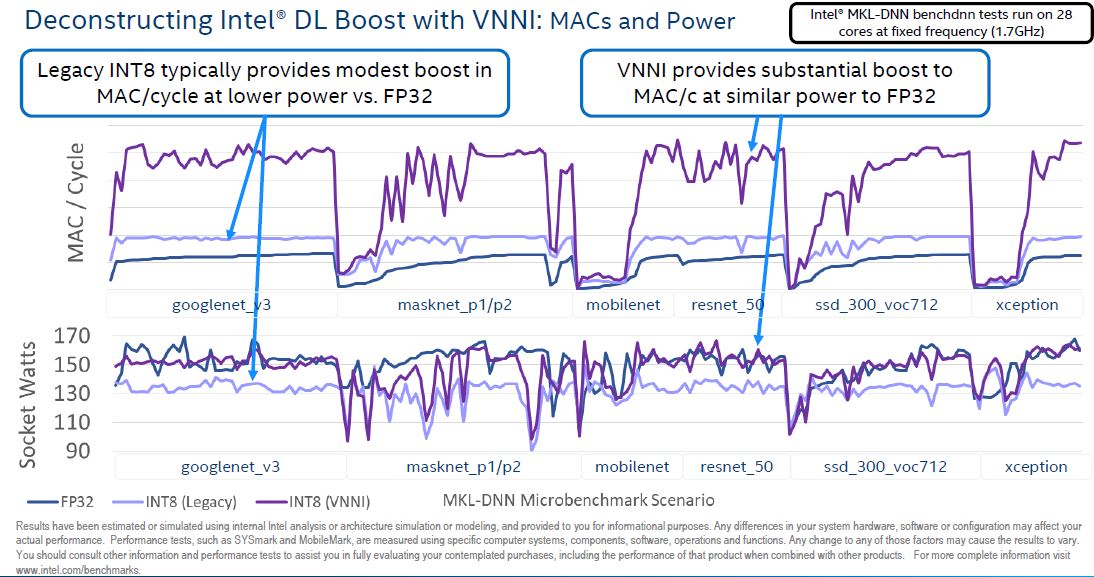
On the L2 cache size, the smaller INT8 data increases the amount of L2 cache hits because more weights can be stored in cache rather than main memory.
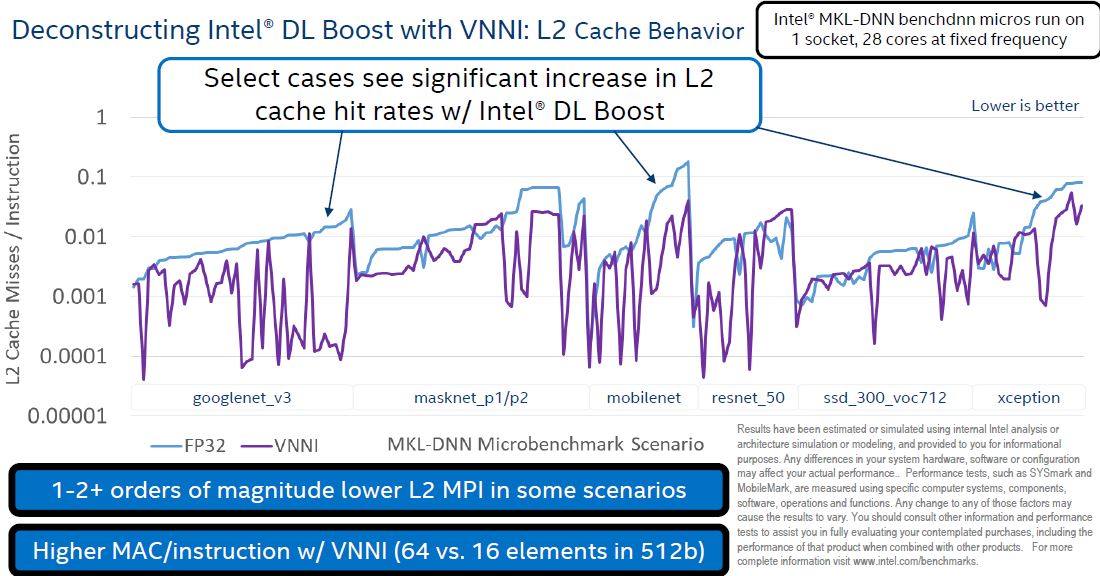
Using Intel DL Boost, one also reduces the amount of memory bandwidth required with INT8 versus FP32, making computation more efficient.
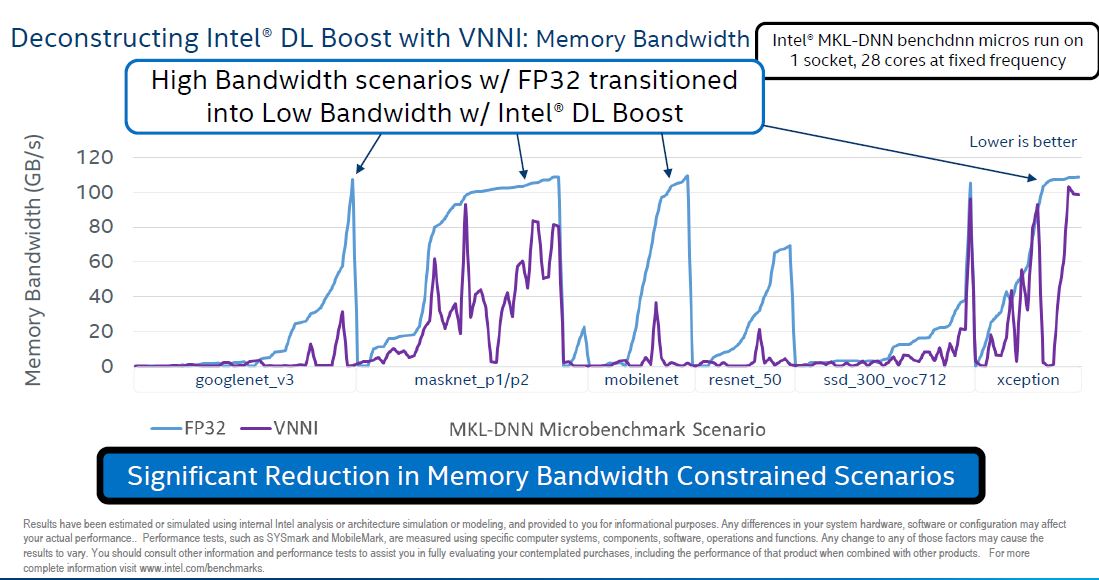
In my discussions with the top three largest server vendors, they all say they have customer interest in DL Boost, however, this is going to be a feature where the software stack needs to catch up. When Intel releases new instructions, this is often the case so it is little surprise. VNNI is not exactly new. Intel Xeon Phi Knights Mill for Machine Learning had a similar feature, but this is a much broader sense of who will have access to it as Xeon Scalable CPUs are much higher volume parts.
Next, we will discuss the new Intel Xeon Platinum 9200 series followed by our final thoughts on what we presented in this article.
The Intel Xeon Platinum 9200 Series for HPC
Feeling the pressure of a 64 core CPU announcement from AMD, the Intel Xeon Platinum 9200 series is a dual socket platform glued together with UPI between the sockets and two silicon die per socket. In essence, this is a quad-socket Intel Xeon Scalable server tuned for maximum compute and memory bandwidth in a half-width form factor.
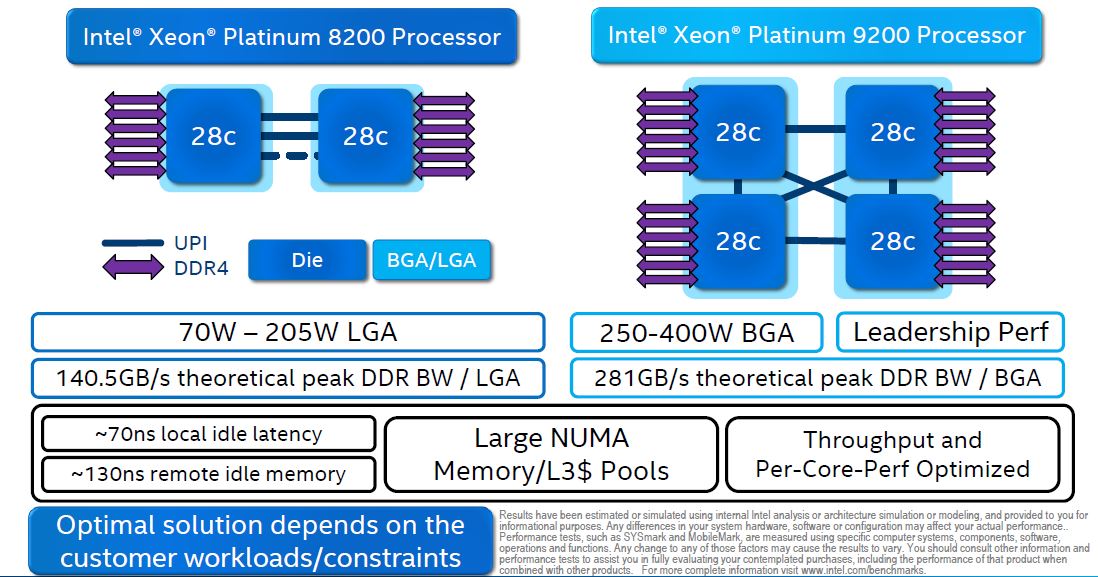
Here is the family overview:

Here are the Intel Xeon Platinum 9200 SKUs:
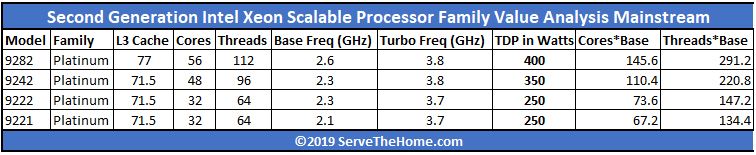
There are a few key points to note here. First, the Intel Xeon Platinum 9200 series uses a lot of power, from 250W to 400W TDP.

Second, as BGA solutions, these chips are not socketed like other Xeon Scalable CPUs. Instead, they are affixed to PCB by Intel and sold as a dual socket PCB with CPUs by Intel.
In our Intel Xeon Platinum 9200 series article, we show the platform and nuances of the packaging. One thing is clear: these are not mainstream CPUs. Most users will be better off with standard Intel Xeon Scalable parts like the Platinum 8200 series.
Speaking with server vendors, not all will support the new Platinum 9200 series platform. A server vendor’s value-add is often tied to management, PCB, and form factor design. By providing a nearly complete solution, server vendors can innovate on power, cooling, and chassis, but that does not provide much differentiation in a crowded market. All server vendors point to the Platinum 9200 series being a lower-volume part targeted at specific HPC installations.
Final Words
Without a doubt, Intel Optane DC Persistent Memory is one of the most exciting technologies of this generation. At the same time, we urge our readers to look beyond maximum core counts and to the heart of the lineup. As we have shown in this article, there are absolutely massive gains to be had purchasing in the heart of the lineup between core count and frequency increases. Intel is certainly feeling competition from AMD, and the 2nd Gen Intel Xeon Scalable processor platforms show how it is responding.
Again, here are our eight key points to the new launch that we want our readers to be aware of:
- More cores in the mainstream part of the SKU stack at the same price points
- Almost all SKUs in the stack have minor clock speed bumps and thus performance improvements accompanying the core count increases
- Similar clock-for-clock IPC performance as the first generation
- Memory speeds and capacities have increased, now to a maximum of DDR4-2933 speeds and 256GB LRDIMM support
- Intel Optane DC Persistent Memory Module support (DCPMM) for persistent, high-capacity, high-performance modules in DDR4 sockets
- New hardware security mitigations and fixes for the side channel/ speculative execution families of vulnerabilities, e.g. Spectre/ Meltdown and L1TF
- Intel DL Boost using the new VNNI instruction to allow faster AI inferencing without GPUs
- New quad CPU packaging into a half-width dual-socket Intel Xeon Platinum 9200 series to increase density for the HPC space
Both today, and over the course of the next few weeks and months, we will have additional deep dives into these CPUs, platforms that support them, and Optane DCPMM. Stay tuned for more 2nd Gen Intel Xeon Scalable coverage on STH.



{kind=link}
Intel Ark lists a single AVX512 FMA Unit for the Gold 52xx series so that’s probably what you get in retail.
I’m looking at the performance effect of NVM like Optane DCPMM in a cloud environment. I’m configuring multiple virtual machine environment and struggling with the input workload. I’m wondering what “KVM Virtualization STH STFB Benchmark” is, and how can I get the detail workload information?