
The second highest-end SKU for the Intel Xeon E5-2600 V4 series is the Intel Xeon E5-2698 V4 CPU. The chip has 20 cores and 40 threads meaning a dual socket configuration has 40 cores and 80 threads. The E5-2698 V4 sports a 135w TDP and includes 50MB of L3 cache. This is only a 2C/ 4T and 5MB reduction from the top of the line E5-2699 V4 which you can read about in our Intel Xeon E5-2699 V4 Benchmarks. The E5-2698 V4 comparatively has a 10W lower TDP but the same clock speeds as the top chip. We were lucky to have several dual socket configurations available to us for testing. Unlike most of our tests which are run in single node rackmount chassis, we had several Supermicro GPU SuperBlades to use in our evaluation.
Test Configuration
Our test platform for the Intel Xeon E5-2698 V4 was actually a Supermicro SuperBlade system. We had 4x SuperBlade SBI-7128RG-X GPU compute nodes installed in the chassis each with 2x Intel Xeon E5-2698 V4 processors and 128GB of DDR4-2400 installed. This helped make some of our new content, e.g. regression testing through our PyKCB.py Python Linux kernel compile benchmark, an absolute breeze as we could launch 4 iterations on identical systems in the same chassis simultaneously. We will have a review of the GPU SuperBlade system soon, complete with power and thermal imaging as we normally do.
- CPU: Intel Xeon E5-2698 V4
- Motherboard: Supermicro SuperBlade SBI-7128RG-X
- Memory: 64GB – 4x Micron 16GB DDR4 2400MHz ECC RDIMM
s
- SSD: 1x Intel DC S3700 400GB
- Operating System: Ubuntu 14.04.3 LTS

We tried picking some interesting comparisons out of our data set. We did receive some extra launch support from Supermicro as we had extra nodes at our disposal that we were using and that we were hosting in our data center lab for other technology sites. We had four Supermicro CPU SuperBlades (see the bottom chassis) to run the benchmarks on and we also ran a few regression tests on other nodes. Just to give you an idea of the 12 node cluster we had running for this effort:

The GPU SuperBlade nodes and the Xeon D MicroBlade nodes have been great to work with so far and you can expect a full review shortly. These chassis each have four power supplies and integrated 10Gb Ethernet switches. We are glad we have 208V data center power to run these on!
Intel Xeon E5-2698 V4 Benchmarks
For our testing we are using Linux-Bench scripts which help us see cross platform “least common denominator” results. We are using gcc due to its ubiquity as a default compiler. One can see details of each benchmark here. We are likely going to update the Linux-Bench in the near future with a few new tests as well as an even simpler to use/ faster revision, but for now, we are using our old Ubuntu 14.04.3 version that can be found by running:
sudo bash (curl -sk http://linux-bench.com/lb-test.sh)
You can use that command from a Ubuntu 14.04 LTS system with curl installed to compare your system to our results. We are also utilizing our new PyKCB.py benchmark, a Python scripted Linux kernel compile benchmark that we have been working on for several weeks now.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. We (finally) have a Linux kernel compile benchmark script that is consistent. Expect to see this functionality migrate into Linux-Bench soon (we are just awaiting the parser work on it.) The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make with every thread in the system. We are expressing results in terms of complies per hour to make the results easier to read.
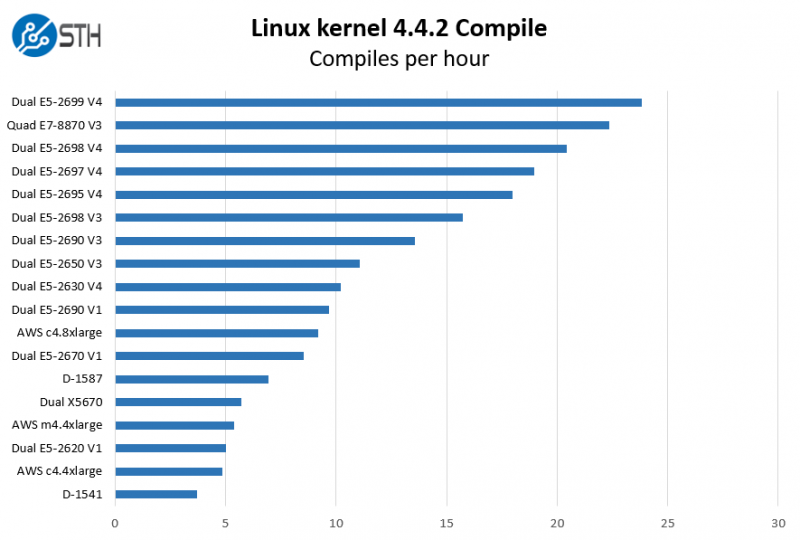
As you can see, the E5-2698 V4 is a very formidable processor, easily besting almost any other chips we have tested in our Linux compile benchmark. The bottom line is that these large chips have the CPU horsepower of clusters of smaller chips.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads.
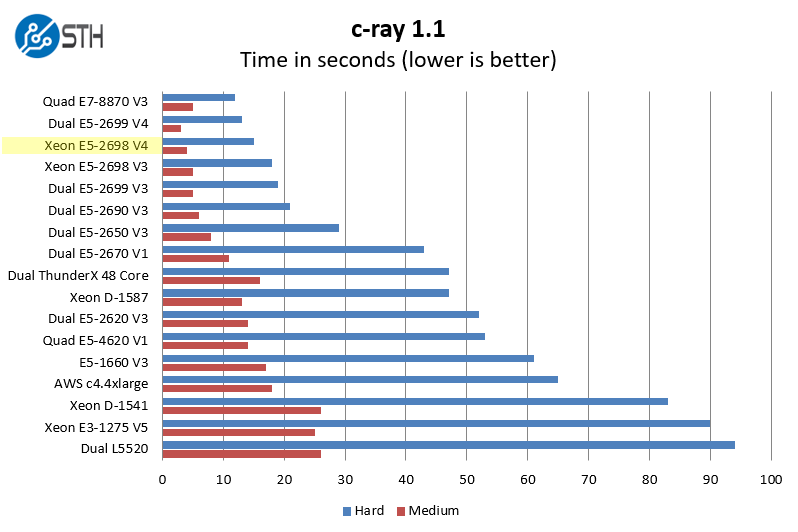
As one can see, on c-ray, a heavily threaded benchmark where these high core count chips work extremely well. This is another result that will likely push for an “extra hard” test by the end of 2016.
7-zip Performance
7-zip is a widely used compression/ decompression program that works cross platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
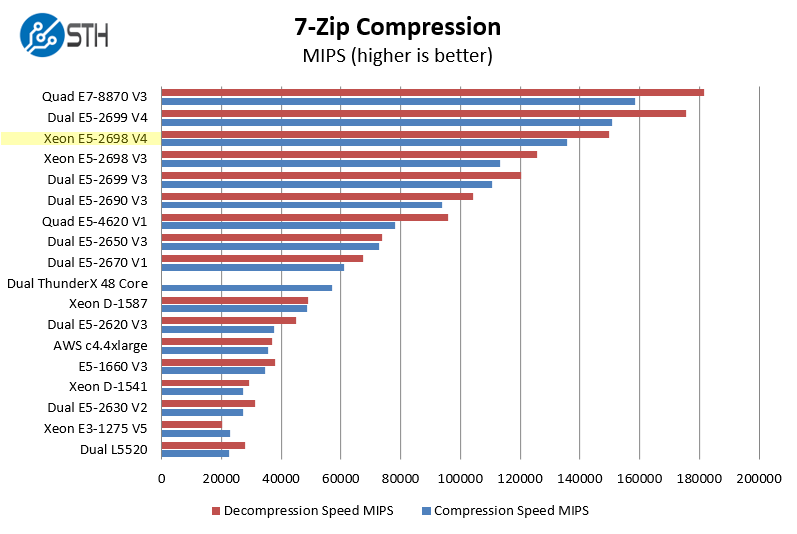
Compression is a major operation we see in today’s workloads and is also highly threaded. We did have the Cavium ThunderX 48 core result omitted as we explained in our 96 core Cavium ThunderX benchmark piece. One can see the extra cores and IPC improvements perform well here. We can see that there is a clear benefit of these chips over the E5-2698 V3 parts.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here.
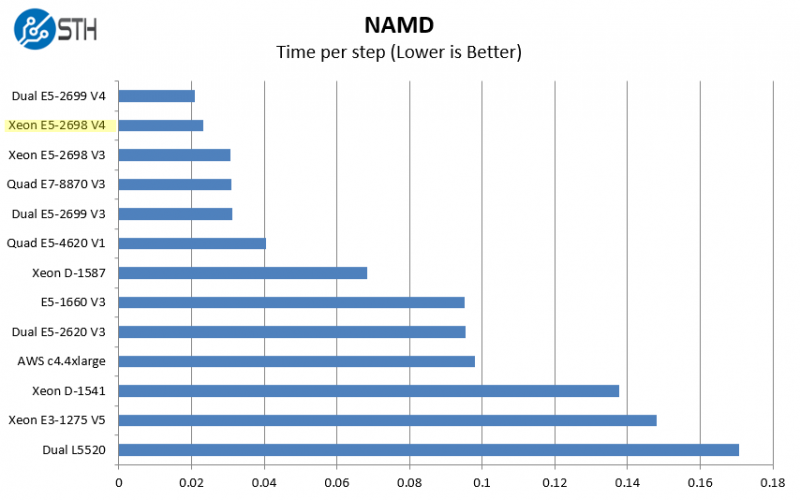
Again, in a compute heavy task we see clear benefits to having these larger chips.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
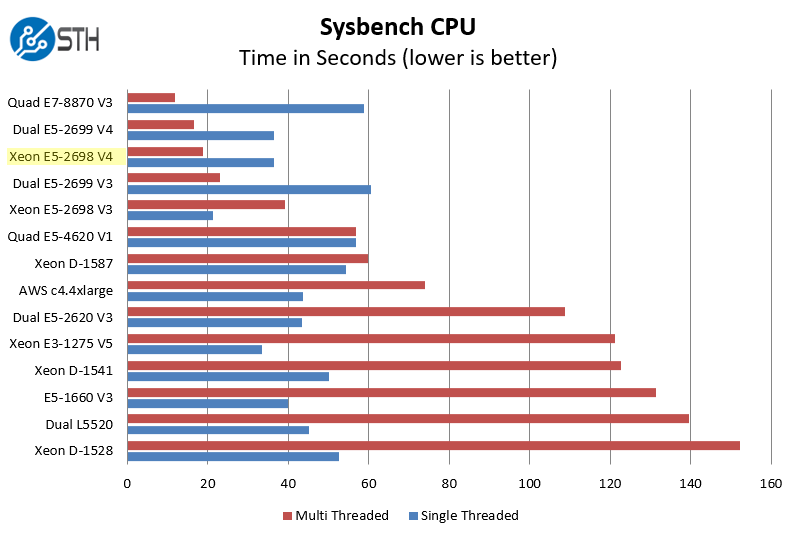
We sorted this chart on the multi-threaded results. Practically that means that the blue bars representing single threaded performance would change the ranking. One can see though that the delta on the single threaded side is about 3x while the delta on the multi-threaded side is more than five times that amount.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
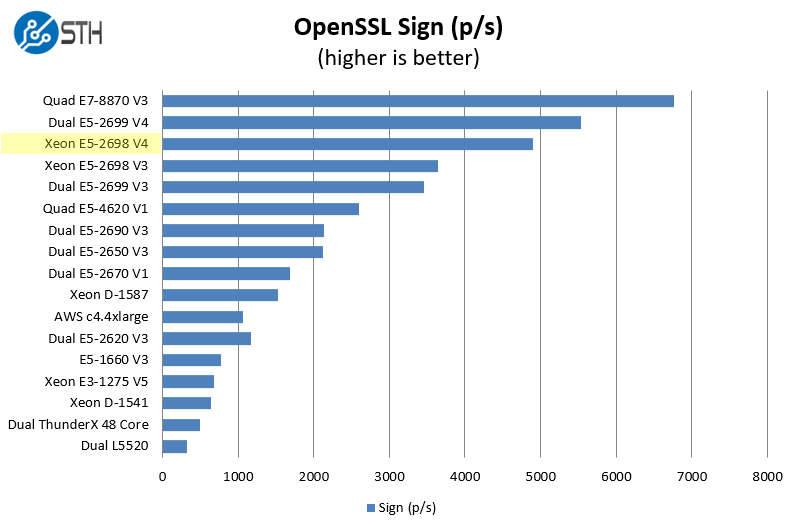
One can see here high-end speed of the Intel Xeon D-1587. Moving to the verify results:
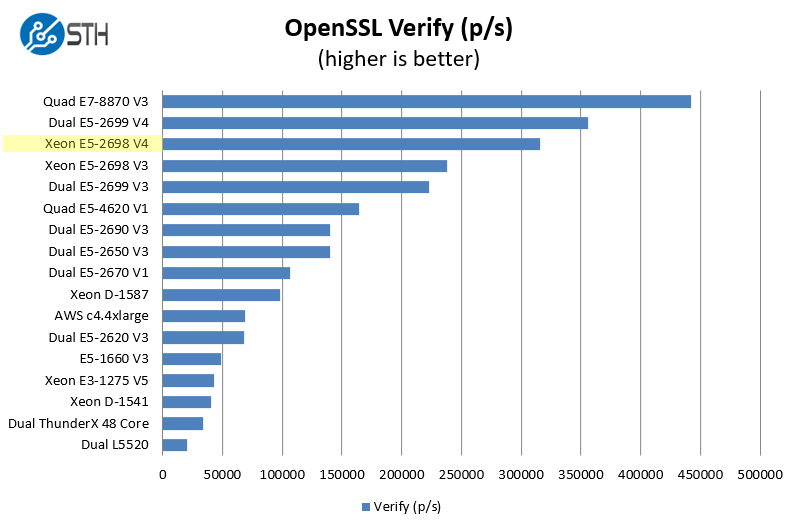
This was a bit unexpected, however Broadwell-DE (Xeon D) is a generation newer processor core than the Haswell-EP chips (Xeon E5-2620 V3) we tested. The OpenSSL results we saw were great. We were able to confirm this result on a second Xeon D-1587 platform.
UnixBench Dhrystone 2 and Whetstone Benchmarks
Of course, these chips are not meant for heavy compute but we pick out the UnixBench 5.1.3 Dhrystone 2 and Whetstone results to show some of the raw performance they are capable of. UnixBench is widely used so it is a good comparison point.
Here are the single threaded workloads:
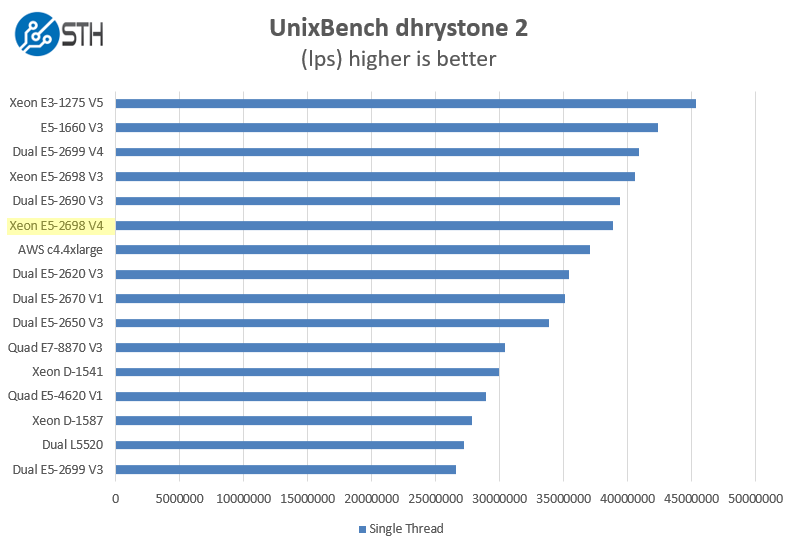
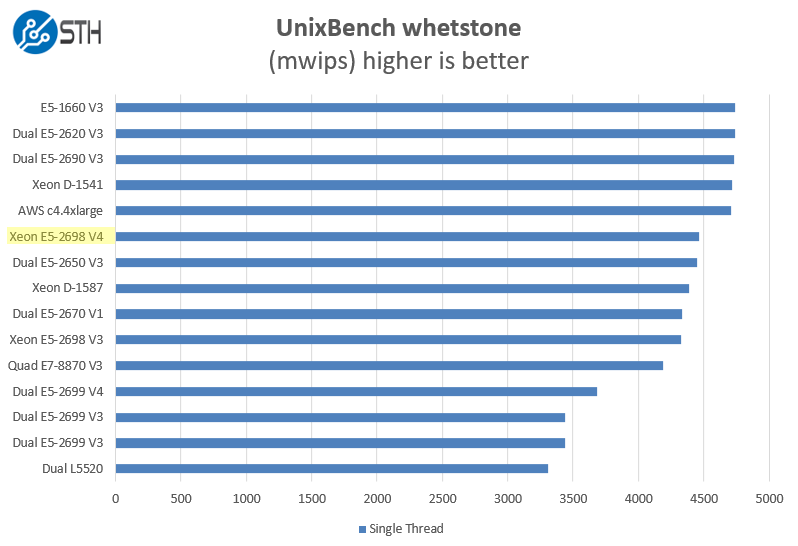
One can see the E5-2698 is not in its element on the single threaded side.
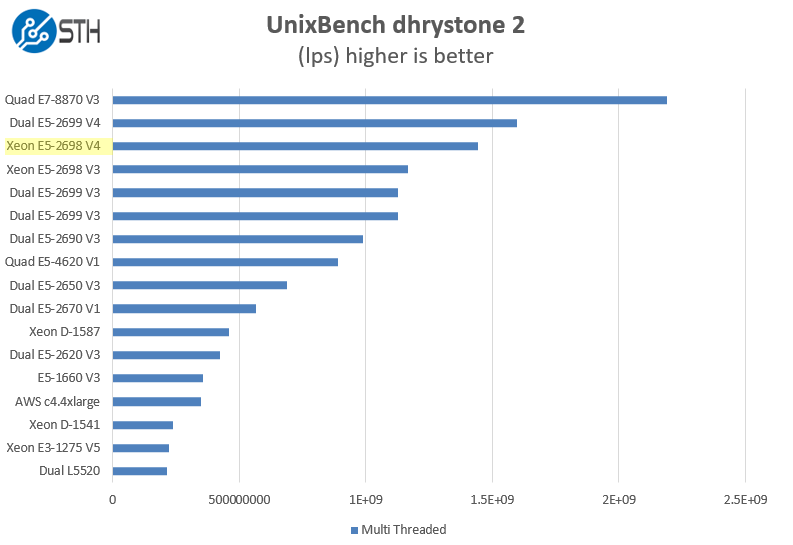
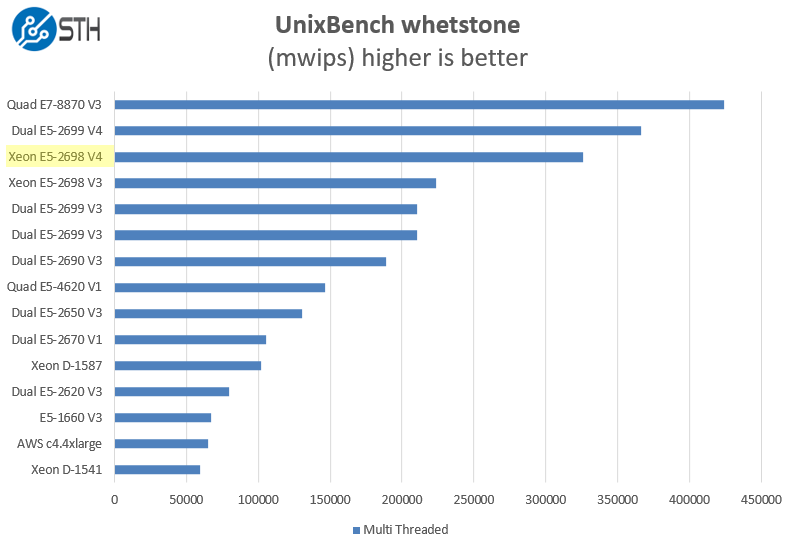
We see much better performance on the multi-threaded tests and again see a larger than expected generation improvement on the floating point tests.
Conclusion
We will have more on the SuperBlade GPU systems as well as the E5-2698 V4 processors so stay tuned. At the end of the day, these processors are very large. Even with the higher per-CPU price tag, the TCO of consolidation is going to drive market demand, especially as older generation servers are replaced. Already we can see some tests with a 3-4x improvement in speed over Sandy Bridge (V1) generation parts which is excellent. We look forward to continuing our coverage of the Intel Xeon E5-2600 V4 series in the coming weeks. These E5-2698 V4 chips have run more benchmarks than any other platform we have tested. Linux-Bench will have a full set of 50+ benchmarks for each run we do. We will make public a dataset of E5-2698 V4 results that would not have been possible without having four identically configured blade servers experiencing the same enviornmental conditions. After using these four E5-2698 V4 nodes for some time now, we can say the capability of this platform is awesome.
You can find more of our launch day coverage here:
- Intel Xeon E5-2600 V4 Line-up and Architectural Overview
- Intel Xeon E5-2699 V4 Benchmarks
- Intel DC P3700 and D3600 dual port NVMe
- Intel DC P3520 and DC P3320 NVMe SSDs
Subscribe to STH to get the latest benchmarks and platform reviews as they are published. We have a huge back log of content coming.



{kind=link}